In 2024, GitLab developers discovered two critical vulnerabilities in their system. Due to verification errors, attackers could hijack user accounts and modify repository contents. This type of attack is known as RepoJacking.
We conducted a comprehensive analysis of GitHub, another major code hosting platform, and identified 1,300 vulnerable open repositories. What are the implications for developers and their projects? Let’s explore.
Why attackers exploit dependencies
Attackers aim to achieve their goals with minimal effort and risk. The fewer steps required, the lower the chance of detection and failure. Cybercriminals prioritize efficiency, making initial access critical to their overall attack strategy.
Most cyberattacks — phishing, credential stuffing, and exploiting perimeter vulnerabilities — are not guaranteed to succeed. But what if the victim unintentionally hands over access? This is exactly what happens when a developer unknowingly integrates malicious third-party dependencies.
This type of supply chain attack is particularly difficult to detect because there is no direct interaction between the attacker and the victim. The growing reliance on third-party code exacerbates this issue, with dependencies accounting for 60–80% of global software services.
The software supply chain includes libraries, components, development tools, and software registries such as PyPI and NPM, which play a crucial role in managing and distributing dependencies. Vulnerabilities in these elements provide attackers with a cost-effective way to infiltrate an organization’s IT infrastructure.
Supply Chain Attacks in Software Development
To mitigate supply chain attacks, the SLSA (Supply-chain Levels for Software Artifacts) framework provides security controls at every stage of software production. However, SLSA does not address protection mechanisms for build dependencies — a critical gap we aim to fill.
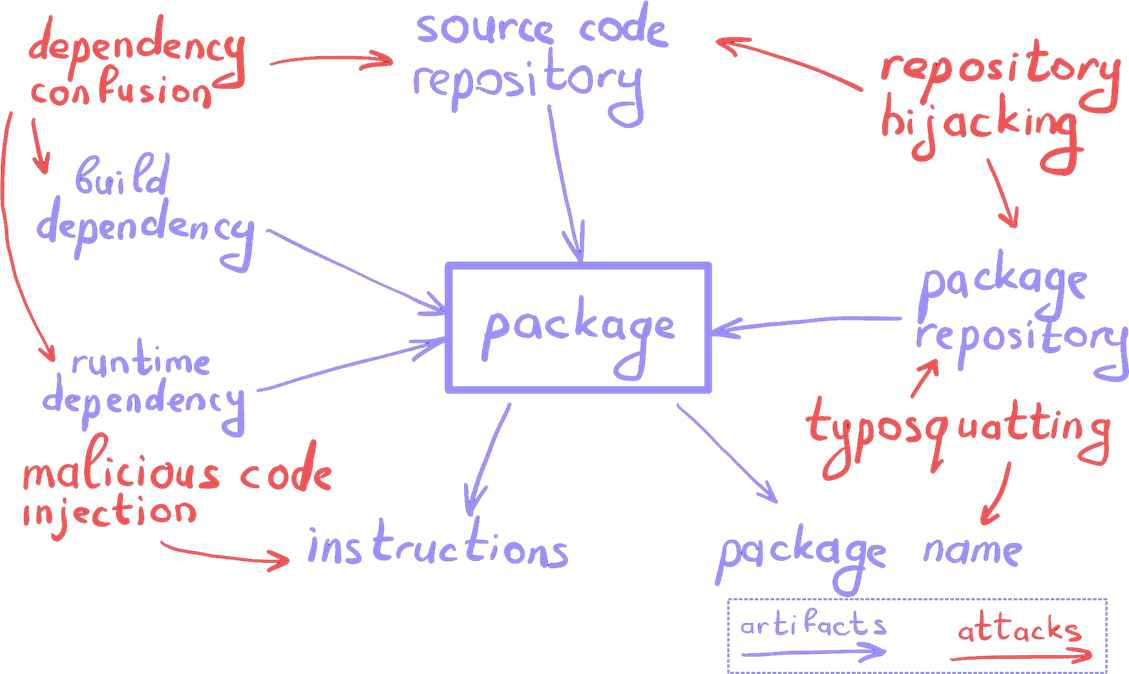
Among the various threats to the software development pipeline, the following attacks specifically involve hijacking artifacts:
- RepoJacking (Repository Hijacking) — an attack on a repository or package management system to gain control over its contents.
- Dependency Confusion — injecting malicious code by exploiting package dependency mechanisms. Recursive Dependency Attacks — targeting dependencies of widely used software libraries.
- Typosquatting — creating malicious repositories with names similar to legitimate ones to trick developers.
- Malicious Code Injection — altering the logic of a program package, such as modifying a compiler to introduce malware.
We focused our research on RepoJacking attacks by systematically scanning publicly accessible GitHub repositories using automated dataset queries and security analysis tools to identify potential hijacking risks.
Understanding RepoJacking attacks
RepoJacking allows an attacker to take control of a repository and manipulate its contents, potentially spreading malicious code through widely used dependencies.
How RepoJacking happens:
- A developer integrates third-party code from a repository into their project.
- The original repository owner deletes, transfers, or abandons their account.
- An attacker re-registers the same username and replaces the repository contents with malicious code.
- All applications that depend on this repository unknowingly incorporate the malicious code.
Done! An easy win for attackers looking to infect dependencies on a massive scale.
Previous studies by Microsoft and cybersecurity firms have relied on small-scale sampling due to resource constraints. Most analyses cover 2–5% of available repositories and extrapolate risk assessments.
Our approach was more comprehensive: we examined all publicly available GitHub repositories. We identified vulnerable dependencies and developed a methodology to help developers detect them in their own code.
Data sources and methodology
We analyzed repositories referenced in PyPI and NPM package managers, leveraging the public GitHub dataset in Google BigQuery. Our dataset included:
- 6,349,287 repositories collected
- 4.7 million unique repositories analyzed
Extracting GitHub repository links
We had three tools to check for links to GitHub repositories: Google BigQuery, PyPI Manager, and NPM.
A standard query (SELECT * from ‘bigquery-public-data.github_repos’) was enough to get the full list of repositories from Google BigQuery. It was virtually effortless, except for the time and resources needed to process several million references.
We wrote a parser that used the method of substituting the package name (https://pypi.org/project/{name_of_the_package_being_searched for}) and then extracting the href value from the DOM tree element of the page that leads to https://github.com/{username}/{name_of_the_package_being searched_for}.
Difficulties arose with the NPM package manager. At first, we acted similarly to PyPI: we scraped package names (https://www.npmjs.com/package/{name_of_the_package_we_were_looking_for}) with further removal of the href value from the DOM tree element of the page leading to https://github.com/{username}/{name_of_the_package_we_were_looking_for}.
We encountered technical challenges, particularly with NPM’s anti-scraping mechanisms, and took care to follow ethical guidelines. We ensured that our data collection adhered to responsible disclosure practices, avoided excessive request loads, and respected rate limits wherever possible. After facing rate limits (HTTP 429 errors), we utilized The Onion Router (Tor) to rotate IP addresses. However, excessive acceleration resulted in gateway timeout errors (HTTP 504). By balancing request speed with Tor, we successfully extracted NPM package data.
Detecting broken and reclaimable repositories
However, not all broken links present a security risk. The real danger arises when the original username associated with the repository can be re-registered by an attacker.
To determine whether a broken account could be re-registered, we created a temporary mailbox and compiled a list of 7,820 usernames. To test this, we:
- Created a temporary email account.
- Using an automated process, we sequentially input each username into the GitHub signup form at https://github.com/signup, checking for the response “{username} is available”, which indicated that the account was available for registration.
- Since each account may own multiple repositories, we cross-referenced the identified usernames with repository links in Google BigQuery to determine how many could be reclaimed. We then logged the available usernames in a separate dataset.
We applied the same methodology to PyPI and NPM package managers, ultimately identifying 1,363 repositories associated with vulnerable accounts. These repositories remain accessible, though further research is needed to determine their level of usage and demand. These repositories remain accessible, raising serious security concerns.
Research in Numbers
When translating our research results into numbers, the key findings are as follows:
- 6,349,287 repositories analyzed:
- 4,650,987 unique repositories identified
- 3,325,634 repositories found through BigQuery queries in Google Cloud Console, all unique
- 484,233 repositories found via PyPI, with 293,470 unique ones
- 2,539,420 repositories identified via NPM, of which 1,031,884 were unique
- 7,820 broken links detected:
- 6,418 repositories with broken links found via Google BigQuery
- 1,046 broken links detected in PyPI
- 356 broken links detected in NPM
- 986 unique accounts were eligible for re-registration, making their repositories vulnerable to RepoJacking:
- 636 accounts found via Google BigQuery
- 294 accounts identified in PyPI
- 56 accounts detected in NPM
- 1,363 repositories confirmed vulnerable to RepoJacking attacks:
- 937 repositories via Google BigQuery
- 352 repositories via PyPI
- 74 repositories via NPM
The total proportion of vulnerable repositories among all analyzed was 0.03%. While this seems minor at first glance, the real concern is not just the number of libraries but how frequently they are used. This will be the focus of our next study. In the meantime, we share a methodology for checking your code for known RepoJacking vulnerabilities.
How to Check Your Code for RepoJacking Vulnerabilities
For developers looking to stay ahead of attackers and secure their SDLC, we recommend four simple steps:
- Extract all Git repository links from your code.
- Verify the validity of these links and ensure none return a “404 Error” or “301 Error.” You can use the nuclei scanner with a template for detecting subdomain takeover attacks (RepoJacking is a subtype of this attack).
- Remove all repositories returning a 404 or 301 error from your codebase.
- Repeat steps 1–3 for every new release.
Proactive Measures for Secure Dependencies
This approach only identifies repositories that attackers may exploit in the future if they re-register the associated accounts. If an account was already hijacked before our study, the supply chain may already be compromised. To prevent this from happening, we recommend proactive security measures:
- Maintain an updated inventory of all third-party components in use. You can learn how we solved this issue using development tools [here].
- Implement Software Composition Analysis (SCA) tools, even if your company hasn’t fully adopted DevSecOps processes or security testing methods like SAST/DAST.
- Establish an internal repository for all dependencies, keeping it updated and restricting access to developers only.
- If your organization has a Security Operations Center (SOC), work on covering MITRE ATT&CK’s Supply Chain Compromise techniques, such as “Compromise Software Dependencies and Development Tools.” Build a secure development infrastructure and select the right tools for component analysis.
Future Research Directions
Our study helps verify the absence of vulnerable dependencies in your code. However, we see further research opportunities and welcome your feedback on which areas would be most useful:
- We are expanding our analysis of collected data to understand how often programs call the vulnerable links we identified. We are calculating the prevalence weight for each unique account and repository.
- To evaluate the usage frequency of vulnerable dependencies, we plan to obtain a list of public repositories relying on them.
- Our goal is to extend link availability verification beyond GitHub. Since we began this discussion with GitLab vulnerabilities, we will include additional platforms over time.