В январе разработчики GitLab нашли в своей системе две критические уязвимости. Из-за ошибок в верификации злоумышленники могут захватывать учётки пользователей и менять содержимое репозиториев. Такой тип атак называется RepoJacking. Мы изучили другой хостинг кода — GitHub — и нашли 1 300 потенциально уязвимых открытых репозиториев. Чем это опасно для разработчиков и их проектов — под катом.
Почему хакеры охотятся за уязвимостями в зависимостях
Атакующему нужно достичь цели за минимальное время и без лишних затрат. Каждый дополнительный шаг увеличивает вероятность, что злоумышленника обнаружат, и усложняет операцию. Чтобы её не раскрыли, нужно больше ресурсов. Первичный доступ киберпреступника определяет дальнейший сценарий кибератаки и количество шагов до цели. Есть заметная разница между проникновением на рабочую станцию случайного сотрудника без доступа к интеллектуальной собственности и закреплением в инфраструктуре разработчика.
Большинство видов кибератак — фишинг, credentials stuffing, эксплуатация уязвимостей в периметре — не гарантируют результата. Но что, если жертва сама даёт хакеру доступ к инфраструктуре компании? Случайно, разумеется. Разработчик просто добавляет в свой код ссылки на сторонние программные пакеты. И не знает, что их контролирует злоумышленник. Этот вид атак — манипуляция зависимостями в цепочке поставок — намного сложнее в обнаружении, ведь прямого контакта с жертвой нет.
Киберпреступникам на руку играет тренд на переиспользование готового кода. Например, доля зависимостей в миросервисах достигает 60-80%. Увеличивается как поверхность атаки, так и вероятность попадания хакером в целевую инфраструктуру.
Цепочка поставок — это и программные библиотеки, и компоненты, инструменты для разработки и доставки кода. Уязвимости в ней стали относительно дешёвым средством для получения качественного доступа к IT-инфраструктуре жертвы.
Атаки на цепочку поставок в разработке ПО
Для защиты софта от атак на уязвимости в цепочке поставок есть фреймворк SLSA. Он контролирует безопасность конвейера производства ПО на каждом этапе. И у SLSA есть ограничение: его авторы не рассматривают методы защиты зависимостей сборки. Мы закроем этот пробел.

Из всех угроз для конвейера разработки выделим те, где есть возможность захвата конкретного артефакта:
- Repository hijacking (или RepoJacking) — атака на репозиторий или систему управления пакетами.
- Dependency confusion — это категория атак на зависимости пакета, чтобы внедрить вредоносный код в его репозиторий или сборку. Рекурсия: хакер атакует зависимости пакета, который сам является зависимостью для какого-то ПО.
- Typosquatting — создание вредоносного репозитория для его последующего внедрения в процесс сборки.
- Malicious code injection — любая runtime-атака, нацеленная на изменение логики работы программного пакета. Например, за счёт внедрения вредоносного компилятора.
Мы решили последовательно исследовать эти угрозы и начали с атак типа RepoJacking — проверили все (!) доступные репозитории GitHub на возможность захвата. Мы взяли GitHub как самый популярный хостинг кода, но наш подход применим и к другим источникам зависимостей, например, хранилищам программных пакетов.
Поиск уязвимостей для атак RepoJacking
RepoJacking — это атака на репозиторий, которая позволяет получить контроль над его кодовой базой и распространяться в рамках подключаемой библиотеки или используемого стороннего кода. В результате атакующий может выполнить произвольный код в том контексте, в котором используется данная зависимость.
Как происходит RepoJacking
- Разработчик подключает сторонний код из чужого репозитория к своему коду напрямую или через пакетный менеджер.
- Автор этого репозитория удаляет/переносит/продаёт свой аккаунт.
- Злоумышленник регистрирует заново или получает доступ к тому же аккаунту и размещает в нём вредоносный код.
- Все приложения, которые подключают код из этого репозитория, оказываются заражёнными.
Готово! Лёгкая победа для злоумышленников, стремящихся массово заражать зависимости.
Наше исследование не первое — их регулярно проводят и корпорации уровня Microsoft, и ИБ-компании. Однако подготовка такой аналитики — ресурсоёмкая работа. Поэтому исследователи обычно ограничиваются небольшой выборкой репозиториев на GitHub.
Обычно исследователи рассматривают выборку в 2-5% от доступного объёма репозиториев, вычисляют, например, что 0,1% из них уязвимы, и экстраполируют это значение на всю выборку.
Мы же решили вопрос основательно — исследовали все репозитории, находящиеся в публичном доступе на GitHub. Выявили уязвимые зависимости, а также разработали методикуих поиска в вашем коде.
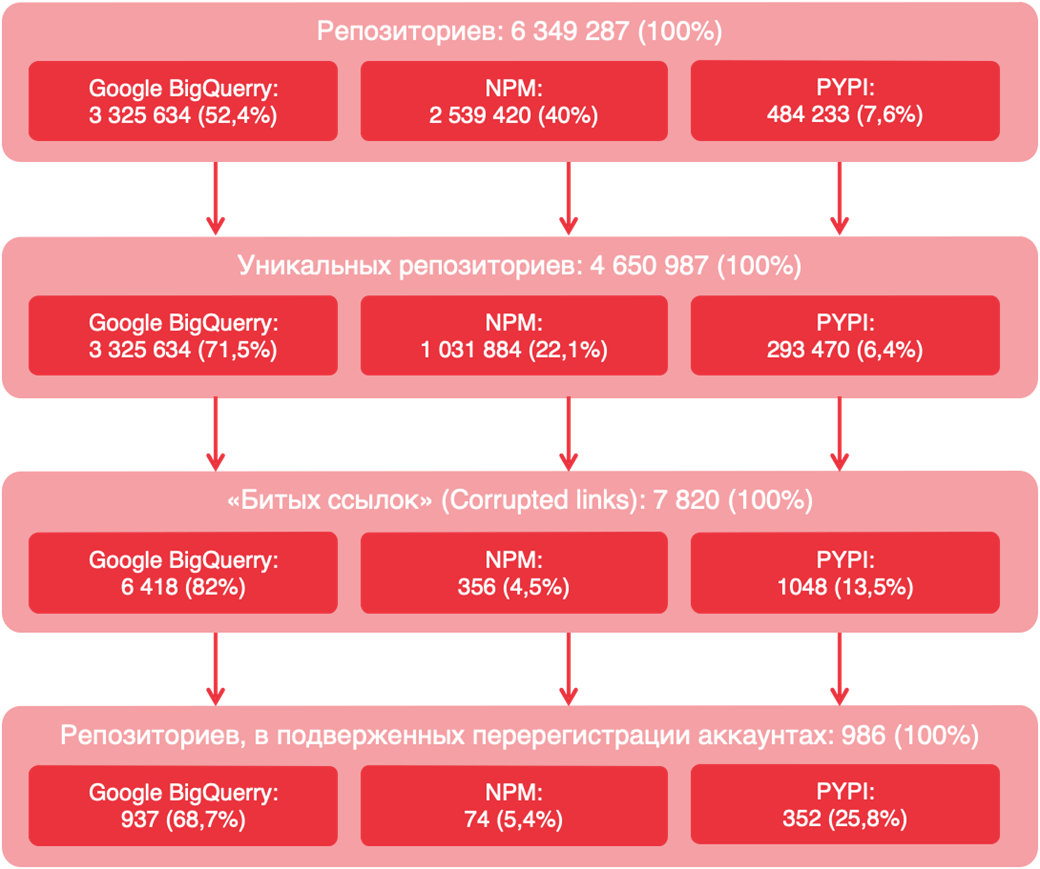
В ходе исследования мы проверили все репозитории, которые используются в пакетных менеджерах PyPI и NPM, а также использовали открытый набор данных GitHub в Google BigQuery. Мы искали ссылки на репозитории, аккаунты которых были перенесены или удалены. Всего собрали 6 349 287 репозиториев. Проверка показала, что 4,7 млн из них — уникальные. В них-то мы и провели поиск репозиториев, доступных для захвата.
Как мы искали уязвимые репозитории на GitHub
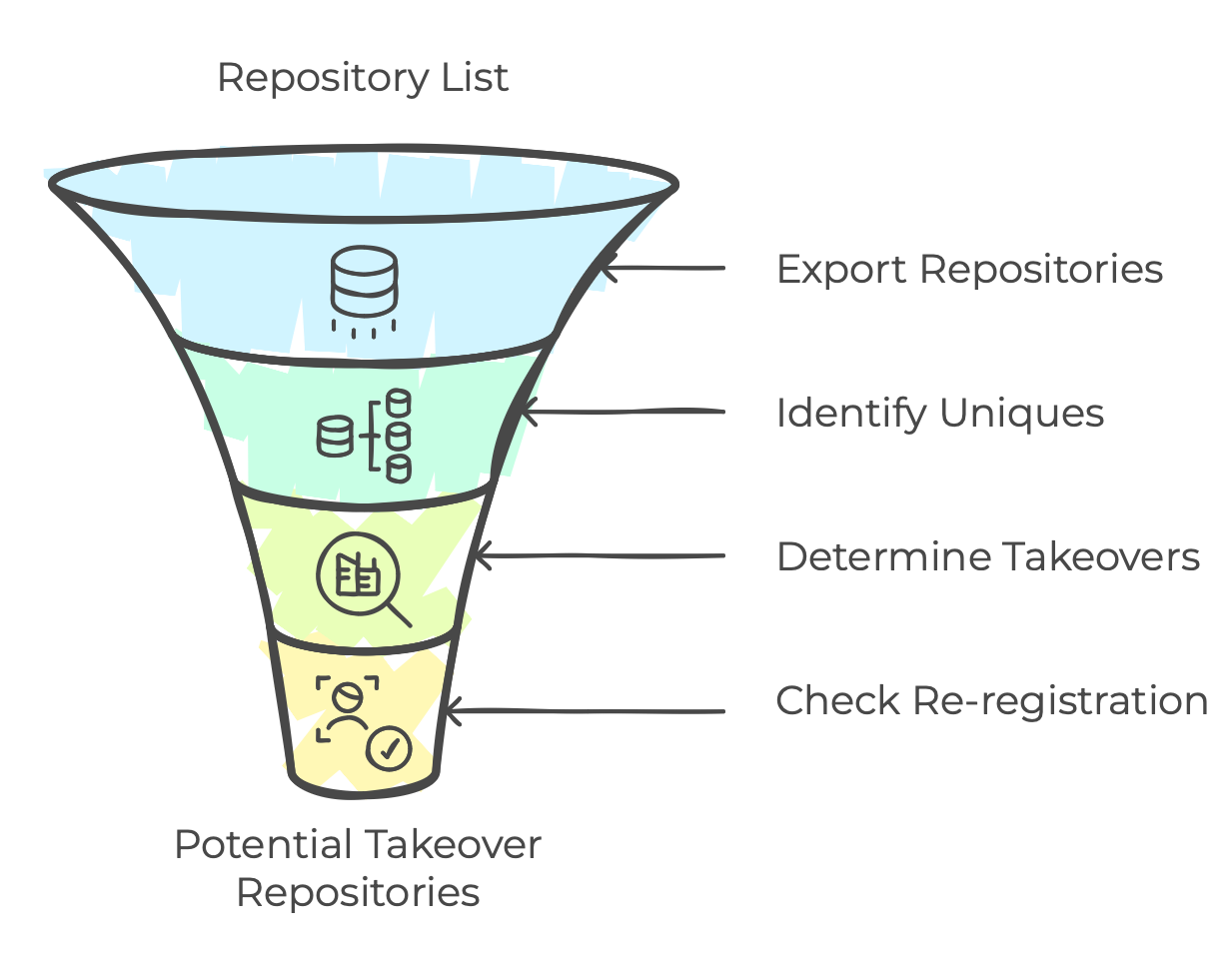
Извлечение ссылок, ведущих на GitHub
У нас было три инструмента, через которые мы проверяли ссылки на репозитории GitHub: Google BigQuery, менеджеры PyPI и NPM.
Для получения полного списка репозиториев из Google BigQuery хватило стандартного запроса (SELECT * From ‘bigquery-public-data.github_repos’). Это практически не составило труда, если не считать времени и ресурсов на обработку нескольких миллионов ссылок.
С PyPI тоже не возникло сложностей — мы написали парсер, в котором использовался метод подстановки имени пакета (https://pypi.org/project/{имя искомого пакета}) с дальнейшим изъятием значения (href) из элемента DOM-дерева сайта, ведущего на https://github.com/{Имя пользователя}/{Имя искомого пакета}.
Трудности возникли с пакетным менеджером NPM. Сначала мы действовали по аналогии с PyPI: перебрали методом подстановки имена пакетов (https://www.npmjs.com/package/{имя искомого пакета}) с дальнейшим изъятием значения (href) из элемента DOM-дерева сайта, ведущего на https://github.com/{Имя пользователя}/{Имя искомого пакета}.
Однако коллеги из NPM Inc защитили свой ресурс от автоматического скраппинга и парсеров: после каждого 3-5 запроса мы получали ошибку 429 от сервера (too many requests). Чтобы не ждать окончания тестирования вечность, мы использовали The Onion Router (aka Tor). Tor позволяет постоянно менять IP, поэтому ограничений на количество запросов не возникало. Это ускорило выполнение парсинга. Но мы слишком разогнались — стали получать от сервера ошибку 504 (gateway time-out). Компромисс нашли, замедлив скорость обращений. В комбинации этой опции с Tor удалось закончить опрос NPM в приемлемые сроки.
Получение битых ссылок и уязвимых репозиториев
Для поиска битых ссылок (corrupted links), по которым репозитории с кодом больше недоступны, мы воспользовались утилитой из набора Kali Linux — nuclei. Этот инструмент позволяет отправлять запросы на основе шаблонов с ожиданием заданного ответа. Для получения необходимого результата в шаблонах nuclei использовались две текстовые фразы: Sign in to GitHub и a GitHub Pages site here For root URLs, — эти сообщения выдаёт GitHub при обращении по битым ссылкам. Таким образом мы получили 7 820 corrupted links, то есть ссылок на репозитории, по которым на самом деле нет кода.
Однако не каждая битая ссылка — это уязвимость. Опасность возникает, если аккаунт, которому принадлежит репозиторий, можно зарегистрировать заново. Если это сделает злоумышленник, он сможет разместить вредоносный код по ссылке.
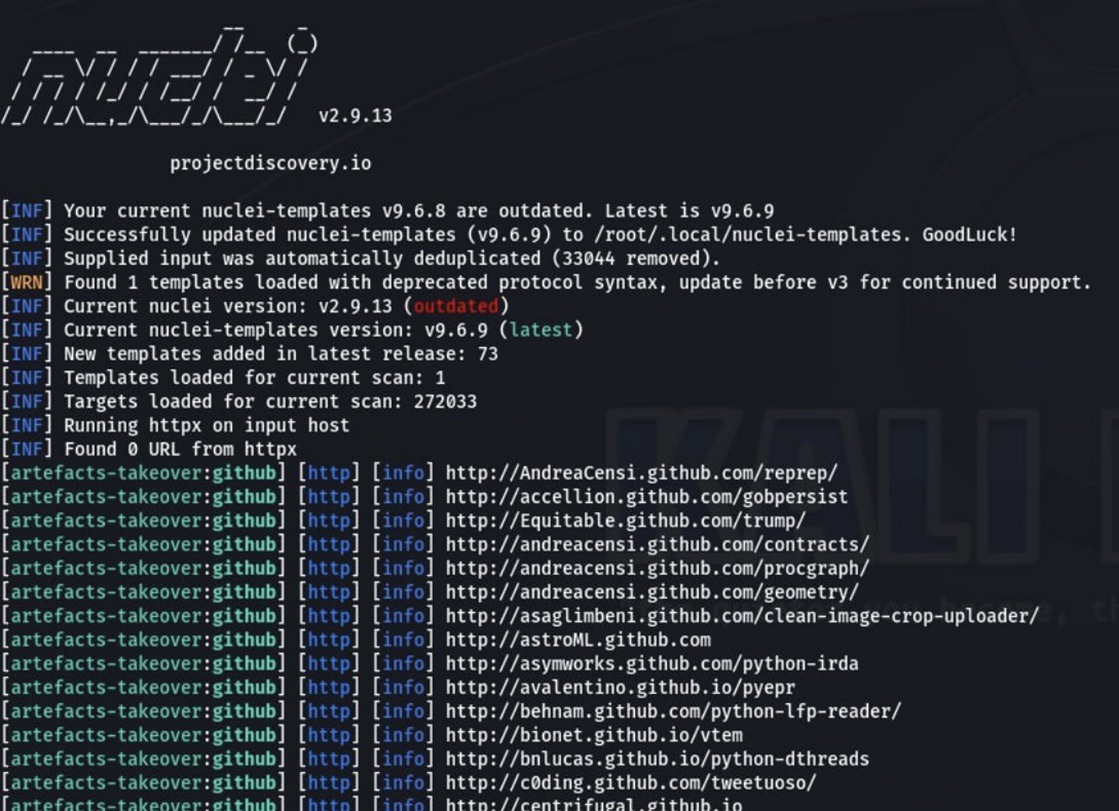
Чтобы узнать, сможем ли мы перерегистрировать на себя «битый» аккаунт, создали временный почтовый ящик и собрали список из 7 820 имён пользователей.
Далее в автоматическом режиме поочерёдно подставляли имена в поле для регистрации https://github.com/signup и ожидали ответ «{имя пользователя} is available» — это значило бы, что логин свободен для регистрации. Имена таких аккаунтов записывались в отдельный файл — это и есть наш список пользователей, подверженных атаке типа Repository Hijacking.
С каждого аккаунта может быть заведено множество репозиториев. Чтобы понять, сколько из них доступно для перерегистрации, мы построчно проверили, какие имена входят в список ссылок на репозитории в Google BigQuery.
Затем аналогичную операцию провели для менеджеров пакетов PyPI и NPM. Мы получили 1 363 ссылки на репозитории, относящиеся к уязвимым аккаунтам. К ним до сих пор может обращаться программный код. Насколько они востребованы — тема для последующих исследований.
Исследование в цифрах
Если перевести результаты исследования в цифры, то итоги таковы:
- обработано 6 349 287 репозиториев кода:
- из них уникальных репозиториев — 4 650 987
- запросами в BigQuery через Google Cloud Сonsole найдено 3 325 634 репозитория, из них уникальных — 3 325 634
- менеджер пакетов PyPI: 484 233 репозитория, из которых 293 470 уникальных
- NPM: 2 539 420 репозиториев, из них уникальных — 1 031 884
- обнаружено 7 820 битых ссылок:
- через Google BigQuery найдены битые ссылки на 6 418 репозиториев
- PyPI — на 1 046
- NPM — на 356
- легитимная перерегистрация пользователей возможна для 986 уникальных аккаунтов (их репозитории уязвимы для атаки RepoJacking):
- из них 636 аккаунтов обнаружены через Google BigQuery
- в PyPI — 294 аккаунта
- в NPM — 56 аккаунтов
- обнаружено 1 363 репозиториев, подверженных кибератакам типа RepoJacking — 1 363:
- через Google BigQuery — 937 репозиториев
- PyPI — 352 репозитория
- NPM — 74 репозитория
Всего уязвимых репозиториев от общего числа исследованных — 0,03%. Мелочь? На первый взгляд. Важно не просто количество библиотек, но и то, как часто к ним обращаются. Это тема следующего исследования, а пока поделимся методикой для бесплатной проверки вашего кода на известные уязвимости RepoJacking.
Инструкция для проверки программного кода на устойчивость к RepoJacking-атакам
Разработчикам, которые хотят опередить атакующих и обезопасить свой SDLC, рекомендуем четыре простых действия:
- Извлеките все ссылки на git из вашего кода.
- Проверьте актуальность этих ссылок и убедитесь, что ни одна из них не возвращает ответ «Ошибка 404» или «Ошибка 301». Для этого можно использовать сканер nuclei с шаблоном для обнаружения атак типа subdomain takeover (атаки RepoJacking являются их подвидом).
- Исключите из кодовой базы все репозитории, которые возвращают ошибку 404 или 301.
- Не забудьте повторить пункты 1-3 в следующем релизе.
Более подробно методика проверки кода описана здесь.
Обратите внимание, что так можно выявить только те репозитории, которыми злоумышленники могут воспользоваться в будущем — когда зарегистрируют аккаунт на себя.
Если они это сделали до нашего исследования, то могли уже скомпрометировать цепочку поставок. Чтобы в будущем этого не произошло, рекомендуем несколько проактивных мер для создания кода без уязвимостей в зависимостях:
- Соберите и поддерживайте в актуальном состоянии список всех используемых сторонних компонентов. Как мы решали подобную задачу с инструментами разработчика, можно прочитать здесь.
- Внедрите инструмент software composition analysis (SCA), даже если у вас в компании пока не построен процесс DevSecOps (безопасная разработка) и не используется какой-нибудь способ тестирования кода типа SAST/DAST.
- Создайте внутренний репозиторий для всех зависимостей, поддерживайте его в актуальном состоянии. Выделите к нему доступ только для разработчиков.
- Если у вас уже сформирован Центр мониторинга (SOC), стоит учиться закрывать набор техник матрицы MITRE-атак Supply Chain Compromise: Compromise Software Dependencies and Development Tools, создавать инфраструктуру разработки и подбирать инструменты анализа компонентов программного обеспечения. Для поддержания информационной безопасности компании контролируйте код ещё с самого начала разработки.
Исследование никогда не заканчивается: следующие этапы
Наше исследование позволяет проверить ваш код на отсутствие уязвимых зависимостей. Но мы видим направления для дальнейшей работы и будем благодарны, если вы отметите в комментариях, какие из них вам пригодятся:
- Мы уже расширяем аналитику по полученным данным. Хотим понять, как часто программы обращаются по выявленным нами уязвимым ссылкам. Мы подсчитываем вес (частота встречаемости) для каждого уникального аккаунта и репозитория.
- Чтобы оценить частоту использования уязвимых зависимостей, планируем получить список публичных репозиториев, которые их используют.
- И конечно, хотим расширить охват проверки доступности ссылок — не GitHub’ом единым. Не зря же мы начали статью с уязвимостей GitLab. Со временем добавим и другие ресурсы.
Будем рады, если вы в комментариях расскажете, полезно ли вам наше исследование? Эффективна ли методика? Хотели бы вы присоединиться к будущим исследованиям?