Finding secrets in code can be done quickly and accurately if you know their exact format and search within your own project. The task becomes significantly harder when scanning across multiple projects or an enterprise monorepo. The challenge becomes even bigger if the search area is a developer platform and your secret format is nondeterministic.
Effective secret detection and leak prevention during development are crucial for protecting projects from data breaches. The secret-scanning workflows presented here are designed for defensive use in trusted CI/CD pipelines. By combining lightning-fast push-protection scans with deeper, high-precision sweeps of large codebases, this approach enables defenders to find and revoke leaked credentials right at commit time or during routine audits. This gives them an advantage over any adversary scraping the codebase for sensitive data.
This article will walk you through the discovery phase for a secret analyzer. We’ll explore the latest secret scanning tools, understand their constraints, and identify ways to improve three key metrics of secret scanning: precision, recall, and speed.
How Secrets Help Protect Non-Human Identities
Non-human identities (NHI) are elements of an IT infrastructure that perform actions without involving humans. The Yandex Cloud team has already discussed their associated risks, using cloud service accounts as an example. NHIs can also include services, scripts, CI/CD runners, cloud resources (VMs, microservices, and pods), IoT devices, and even AI agents.
Just like human users, many non-human identities go through authentication and authorization, which means they need to hold the keys to every door. These keys are often long-lived because, unlike human users, NHIs don’t bother changing their passwords.
The more we automate and rely on NHIs, the more attackers resort to a popular trick: using stolen accounts. According to analysts, stolen accounts have become the top cause of incidents in 2025. Attackers have been increasingly using NHI credentials to obtain secrets from service accounts, bots, and AI agents. A key place where these secrets are stored is the code.

A staggering 61% of organizations have secrets in their public repositories. We can broadly sort these secrets into two categories:
- Deterministic strings, such as certificates and tokens from well-known cloud providers and SaaS applications.
- Everything else (for example, passwords in any format).
This brings us to our goal: to find both secret categories accurately, completely, and quickly.
The “quickly” part is crucial for user experience. The main scenario where search speed is critical is the commit analysis mode (push protection). When a user adds a secret to a commit and pushes it to a repository, we have to prevent that commit from entering the codebase.
In other words, we have to prevent the secret from leaking. Push protection mode is heavily impacted by how well the analysis tool performs. So, for our platform’s public preview, we focused on commit analysis and two other key metrics: recall and precision.
Comparing Secret Scanning Tools
We surveyed the popular tools back in 2022. The top contenders have only solidified their standing since then, and the test results back this up.
To evaluate the secret scanning tools, researchers extracted data from 818 GitHub repositories, built a special dataset called SecretBench, and used it to compare popular projects. The research team manually checked and labeled each found secret as “true” or “false”. The dataset was found to contain 97,479 secrets, of which 15,084 were genuine secrets, and the remainder was noise.
The tools were compared across multiple metrics, but three stood out as the most important: scanning speed, recall, and precision.
Recall is a metric that measures the share of correctly detected secrets (true positives, TP) in all the real secrets stored in the code. This metric shows if the tool can detect all relevant cases.
Recall = TP / (TP + FN)
Precision is a metric that measures the share of correctly detected secrets in all positive objects detected. Precision shows how clean and accurate the scan results are.
Precision = TP / (TP + FP)
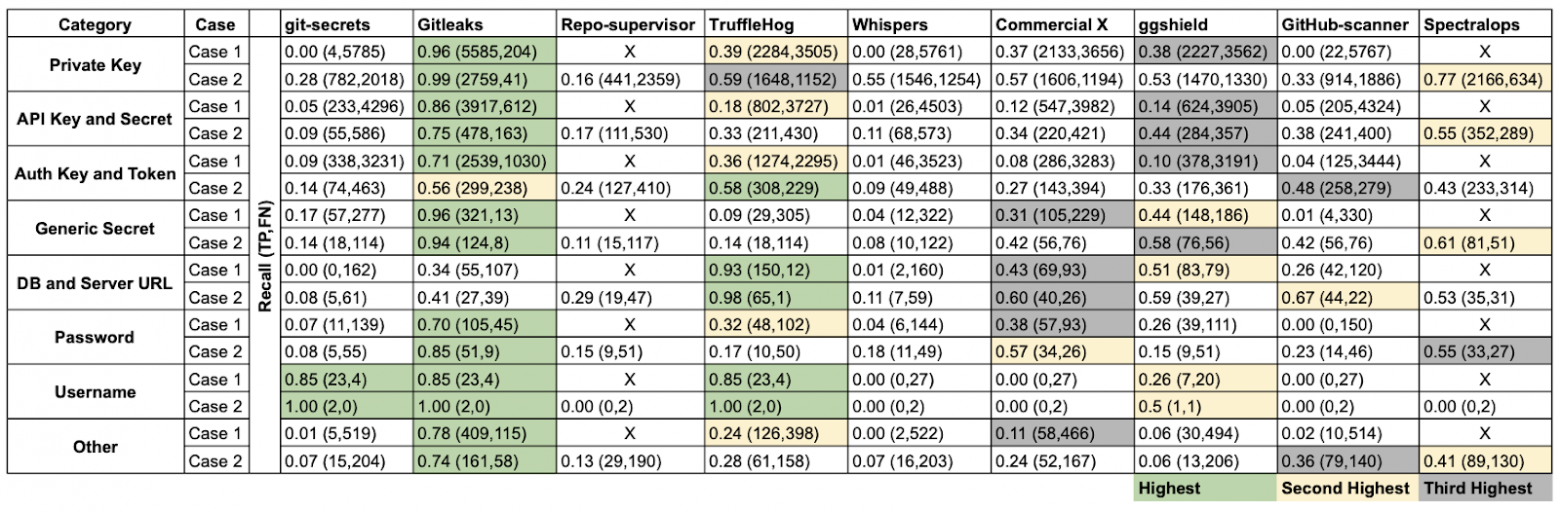
Gitleaks emerged as the leader among open-source projects, achieving 46% precision and 88% recall. Here’s the key takeaway from this research:
“Currently, no single tool offers both high precision and high recall.”
Even so, Gitleaks delivers an excellent balance of scanning speed and recall. With its broad and frequently updated rules, Gitleaks helps us achieve one of the two goals we set for our platform’s public preview: to ensure complete secret detection. Plus, Gitleaks is faster than its competitors. Recent benchmarks, however, suggest this advantage is narrowing.
Meet Kingfisher: All New and Super Fast
Kingfisher, a new tool from the MongoDB team, comes with a number of perks compared to other open-source projects. First, it’s built with Rust, which gives it an edge over Golang tools thanks to faster processing. This translates into a noticeable performance boost, especially when scanning large codebases such as monorepos or complete commit histories.
Secondly, Kingfisher uses Hyperscan, a fast regular expression engine that can process thousands of patterns concurrently in a single pass. Since regex matching can account for up to 90% of total scanning time, having this engine means Kingfisher can outperform Gitleaks, which relies on standard Go regex tools.
Thirdly, besides the regex engine, Kingfisher also uses Tree-Sitter, a code parsing tool. It can build an AST to identify where strings, comments, and variables sit in the code, enabling searches only where they matter. This helps Kingfisher better understand the context of the secret and interpret it more accurately. However, this feature works best with larger files.
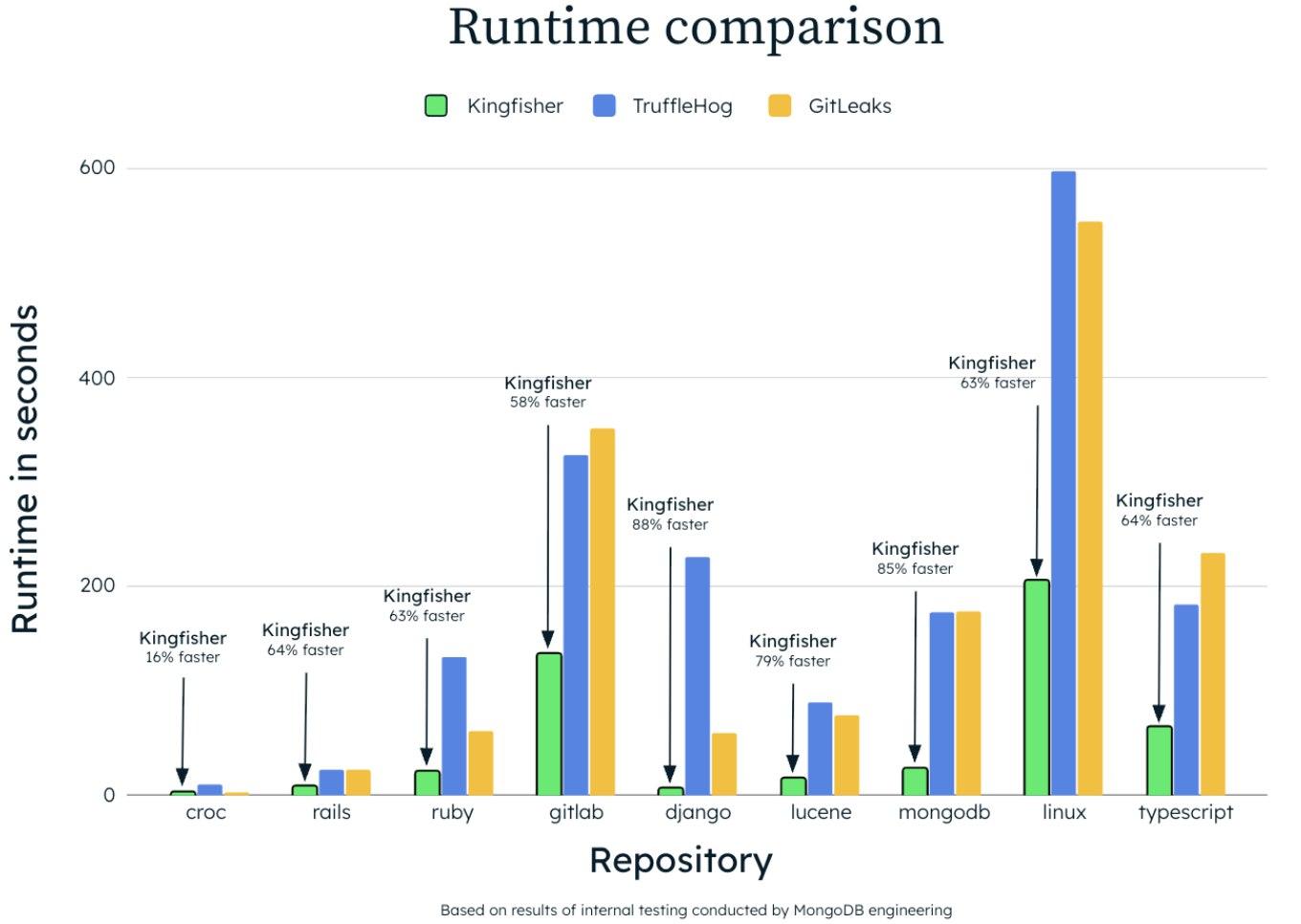
The results of Kingfisher’s internal tests reveal a manifold speed advantage. You can also see that the tool has a slight edge on smaller projects. So, we’ve come up with a hypothesis: while great for scanning large repos and files, Kingfisher might not offer the same benefits in push protection mode.
We decided to check our hypothesis on a small project, sample_secrets, and compared the performance of Kingfisher and Gitleaks. For these tests, we relied on Hyperfine, a utility that accurately compares CLI command performance. Hyperfine runs a command multiple times for accurate data and accounts for the warm-up time during tool loading.
For accurate performance benchmarks, we set up Kingfisher and Gitleaks to scan for secrets only in directories, bypassing commit history. We also turned off extra secret validation for Kingfisher. To launch the process, we ran this command:
hyperfine -w 3 -m 10 --style basic --export-json bench.json --ignore-failure 'gitleaks dir sample_secrets --no-banner --exit-code 0 --report-format json --report-path gitleaks.json' 'kingfisher scan sample_secrets --git-history=none --git-clone=bare --no-validate --no-update-check --format json -o kingfisher.json'

This result likely stems from Kingfisher’s advanced features: it compiles 750 rules in Hyperscan and initializes Tree-Sitter. On small file sets, the initialization phase takes up a significant portion of the overall scan time. Now let’s test this hypothesis on a larger repository.

Kingfisher proves to be faster than Gitleaks when scanning a large project like Kubernetes.

To sum up: in push protection mode, where fast pre-commit analysis is crucial, it’s best to use a tool with minimal overhead and the most regex rules. For medium to large projects, especially those with a long history, accuracy is key. And Kingfisher can improve on the results of Gitleaks. Additionally, the industry is exploring ways to enhance precision by utilizing language models, as well as signatures.
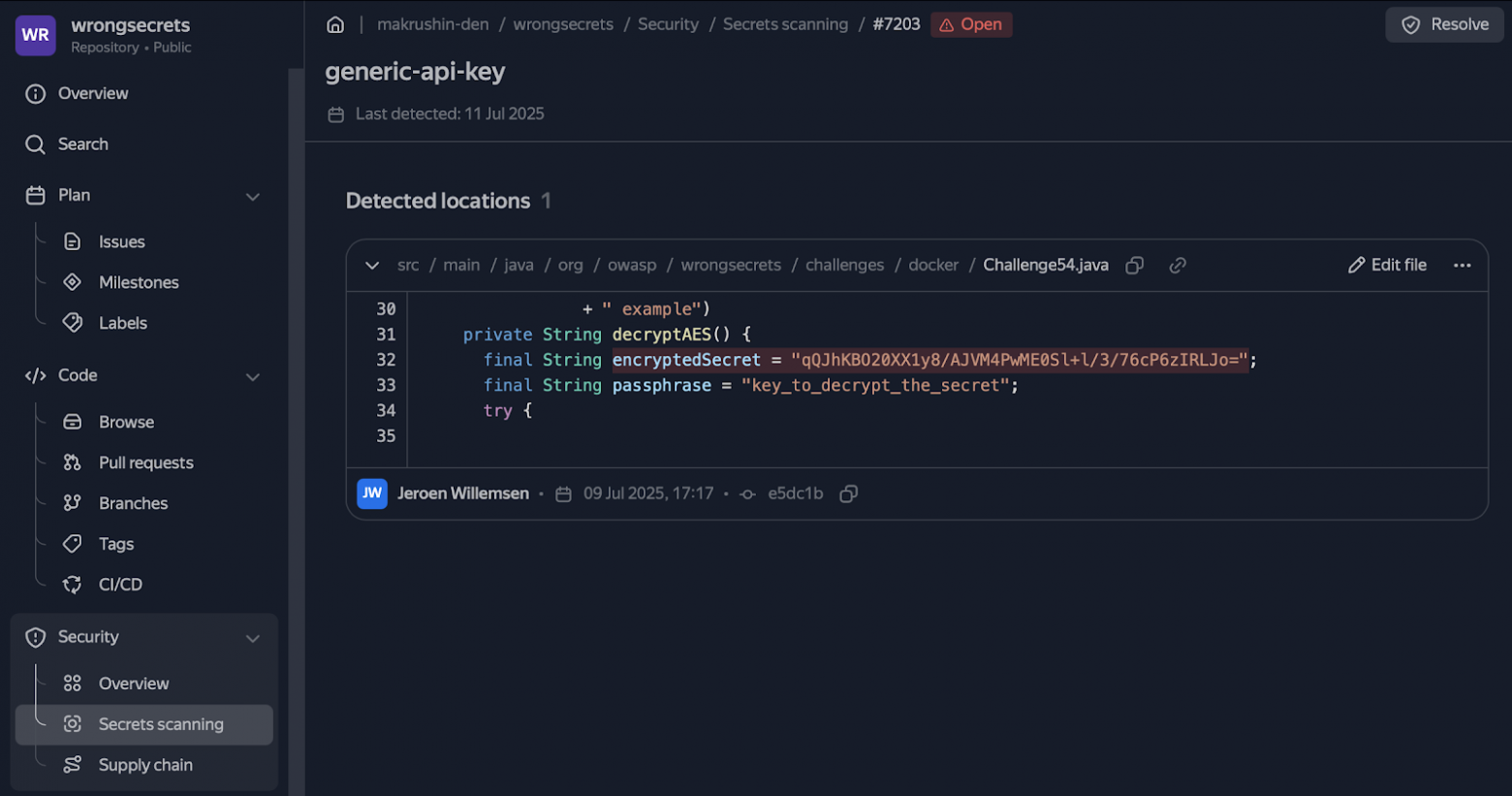
Now, let’s compare the precision and recall metrics for these tools. To do this, we’ll scan OWASP’s WrongSecrets repository and put the results in a comparison table.
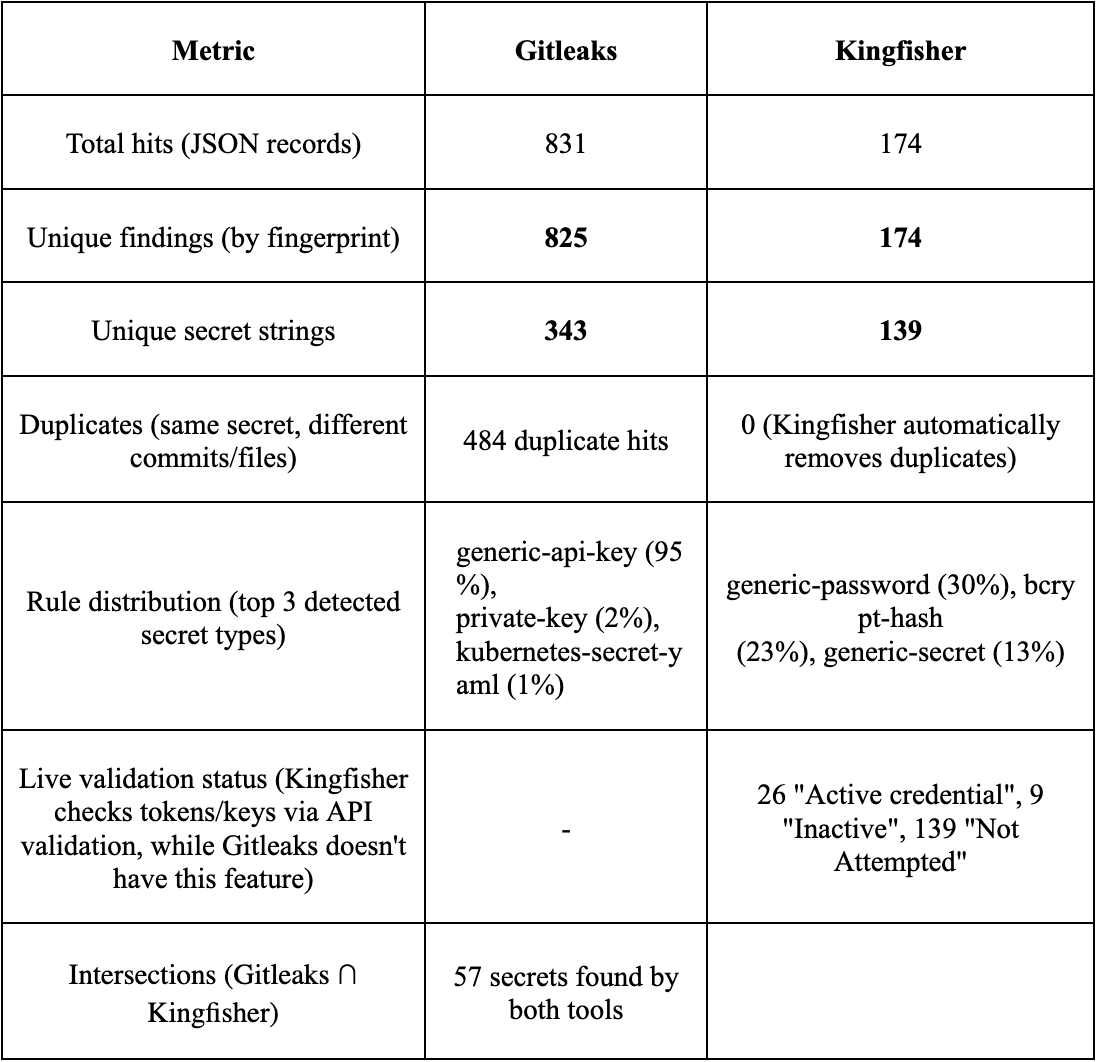
Key takeaways:
- Gitleaks produces more noise from versions/tags.
Out of 825 unique findings, 781 were for the generic-api-key rule. Among these, dozens of entries like wrongsecrets:1.12.0-no-vault are actually Docker tags, not keys. This significantly reduces the precision. - Relatively small result overlap (~17%).
Both tools found 57 secrets. Gitleaks found 286 secrets (but many of those were false positive (FP) versions/tags), while Kingfisher detected 82 secrets and classified 26 of them as active credentials. - Duplicates in Gitleaks inflate the report.
The same base64 password from .bash_history appears 28 times across different commits. Kingfisher reduces the noise using an internal deduplicator. - Without additional scanning settings, Gitleaks offers higher recall and Kingfisher offers higher precision. With this configuration, Gitleaks flags any suspicious string with high entropy, resulting in many false positives. On the other hand, Kingfisher misses some API keys but produces fewer FPs and immediately labels findings as active or inactive.
Ultimately, this comparison reveals how to effectively deploy each of these tools. For pre-commit checks, we use the fast Gitleaks with its robust set of rules. However, we rely on Kingfisher for large-scale scans of releases and commit histories.
Backlog Ideas: Boost Search Precision with Language Models
Large language models (LLMs) can now be used alongside traditional search methods like entropy analysis, regular expressions, and signatures. As our comparison shows, these older methods often make mistakes and confuse password strings with function names. While regular expressions work well with fixed-format strings (such as keys and API tokens), they struggle to handle the wide array of password string patterns.
LLMs cut down on the noise because they take context into account. GitHub’s team confirmed that in their research. But they also noted that using LLMs requires a linear increase in computing resources for each new client. To save resources, the team had to skip the scanning of all media files or files with “test”, “mock”, or “spec” in their names.
Key takeaways from their research:
- Regular expressions provide the groundwork for identifying deterministic strings, but they produce a lot of noise when searching for passwords.
- LLMs reduce noise and successfully find secrets by analyzing context. However, using LLMs for active and large repositories is costly.
- There are two ways to save resources: either reduce the size of the analysis dataset (like GitHub) or optimize the use of computational resources for analysis (like Wiz). What’s even better, you can combine both methods.
- The ways you prompt LLMs affect both their precision and resource consumption. GitHub tested various strategies, including Zero-Shot (just giving the model the task without any examples), Chain-of-Thought (prompting the model to reason its way to an answer), Fill-in-the-Middle (providing the context “before” and “after” and asking the model to fill in the blank in the middle), and MetaReflection (having the model analyze and improve its own initial response). MetaReflection proved to be the most accurate.
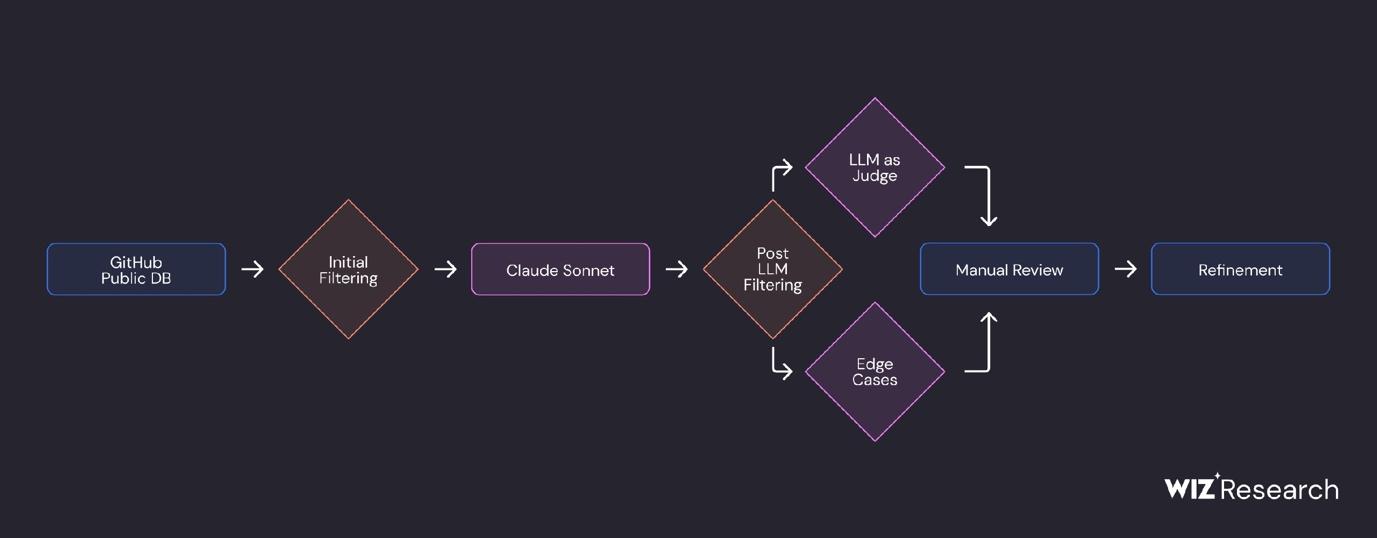
Wiz researchers suggested overcoming the key limitation of LLMs by using small language models (SLMs). They confirmed the hypothesis that SLMs can scan for secrets more efficiently and cheaply than LLMs. Here’s the recipe that helped achieve 86% precision and 82% recall:
- Prepare data for model training: Use an LLM to detect and classify secrets from public GitHub repositories. You can use another LLM to evaluate the results.
- Improve dataset quality: Apply MinHash and LSH (Locality Sensitive Hashing) algorithms to cluster the obtained data, merging similar code fragments into one cluster and removing duplicates.
- Select a model for fine-tuning. We want to detect at least one secret per 10 seconds (available resource: a single-threaded ARM machine).
- Add our “filters” to the base model: Fine-tune small matrices within the chosen model using the LoRA method.
- Evaluate results: Monitor matches at the file level (does it contain secrets?) and at the secret level (what type of secrets?).
These findings don’t mean that signature methods are ineffective. Rather, the model serves as an add-on to the current rules, improving results for Gitleaks and Kingfisher through context analysis.
We can divide the context that affects the verdict into three main blocks (ordered by priority):
1. Syntactic and semantic context. This includes things like N lines of code near the secret, variable name, AST node type, and file language.
2. Git context. For example, the path and type of the file containing the secret, the number of secret occurrences in other commits or files, and the commit author and date.
3. Signature metadata. This involves the rule ID, entropy, and category of the signature that detected the secret.
By combining the information from these three blocks, we can assess the precision and speed of language models. However, for this specific task, we see LLMs as an additional scoring engine. That’s because the variety of strings containing secrets is limited, which means signatures are still the basic detection method. That’s something for our backlog.